What Is Optical Character Recognition?



Introduction
Optical character recognition (OCR) technology is an effective business process that saves time, money and other resources by leveraging automated data extraction and storing capabilities. Text recognition is another term for optical character recognition (OCR). OCR software extracts and repurposes data from scanned papers, camera photos, and image image-only pdf files. OCR software extracts letters from images, and converts them to words, and then sentences, allowing access to and alteration of the original material. It also eliminates the necessity for data entering by hand.
OCR systems turn physical, printed documents into machine-readable text using a mix of hardware and software. Text is typically copied or read by hardware, such as an optical scanner or dedicated circuit board, and then advanced processing is handled by software. OCR software can use artificial intelligence AI training datasets to accomplish more complex methods of intelligent character recognition (ICR), such as distinguishing languages or handwriting styles. OCR is most typically used to convert hard copy legal or historical documents into pdf documents that users may edit, format, and search as if they were generated with a word processor. Collection of Dataset For Machine Learning like OCR is a part of collecting text datasets.
How does OCR work?
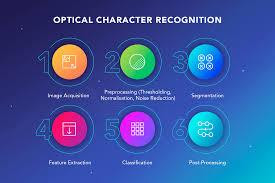
A scanner is used in optical character recognition (OCR) to process the physical form of a document. After these, pages have been copied, OCR software turns the document into two-color or black-and-white. The scanned-in image or bitmap is evaluated for lights and dark areas, with dark parts identified as characters to be recognized and light portions classified as background. The dark areas are then searched for alphabetic letters or numeric digits. This stage usually entails focusing on a single character, word, or block of text at a time. Following that, characters are detected using one of two algorithms: pattern recognition or feature recognition.

When the OCR application is fed examples of text in different fonts and formats, it compares and recognizes characters in the scanned document or picture file. Feature detection occurs when the OCR uses rules to recognize characters in a scanned document based on the features of a given letter or digit. A character’s features include the number of angled lines, crossing lines, or curves. The capital “A”, for example, is recorded as two diagonal lines intersected by a horizontal line in the center. When a character is recognized, it is turned into an ASCII code (American Standard Code for Information Interchange) that computer systems can utilize to perform additional operations. An OCR application examines the structure of a document image as well. It splits the page into elements such as text blocks, tables, and graphics. The lines are separated into words, which are then divided into characters. After identifying the characters, the algorithm compares them to a set of pattern images. The programme displays the detected text after it has processed all possible matches.
What are the benefits of Optical Character Recognition?
The fundamental advantage of OCR Datasets is that it streamlines data entry by allowing for simple text searches, modification, and storage. OCR enables organizations and people to keep files on their PCs, laptops, and other devices, guaranteeing that all paperwork is always available. The following are some of the advantages of using OCR technology:
Cut expenses
Workflows should be accelerated.
Document routing and content processing should be automated.
Data should be centralized and secured (no fires, break-ins or documents lost in the bank vaults)
Improve service by ensuring staff have access to the most recent and correct information
What are the use cases of OCR?
Converting printed paper documents into machine-readable text documents is the most well-known application of optical character recognition (OCR). After OCR processing, the text of a scanned paper document can be modified with a word processor such as Microsoft Word or Google Docs. OCR is frequently utilized as an unnoticed technology, powering many well-known systems and services in our daily lives. Data-entry automation, assisting blind and visually impaired people, and indexing documents for search engines, such as passports, license plates, invoices, bank statements, business cards, and automatic number plate recognition, are all important — but lesser-known — applications for OCR technology.
OCR allows big-data modelling to be optimized by turning paper and scanned picture documents into machine-readable, searchable pdf files. Processing and retrieving relevant information cannot be automated without first using OCR in documents that lack text layers. Scannable papers can now be connected to a big-data system that can read customer data from bank statements, contracts, and other essential printed documents thanks to OCR text datasets. Organizations can use OCR to automate the input step of data mining rather than having personnel evaluate innumerable picture documents and manually enter inputs into an automated big-data processing workflow. OCR software can recognize text in images, extract text from images, and save text files in jpg, jpeg, png, BMP, tiff, pdf, and other formats.

OCR Datasets collection services with GTS
Global Technology Solutions (GTS) has got your business covered with premium quality dataset. With its remarkable accuracy of more than 90% and fast real-time results, GTS helps businesses automate their data extraction processes. In mere seconds, the banking industry, e-commerce, digital payment services, document verification, barcode scanning, Image Data Collection, AI Training Dataset, along with Data Annotation Services and many more can pull out the user information from any type of document by taking advantage of OCR technology. This reduces the overhead of manual data entry and time taking tasks of data collection